RabbitMQ topology guide
I haven’t thought that it would be that hard to find any guidance on RabbitMQ exchanges and queues topology on the net. Almost every article or discussion I’ve met touched different aspect of either RabbitMQ server tuning or some vogue suggestions like it depends on the application purpose, load and different kinds of aspects. I understand that RabbitMQ is flexible enough to solve any problem with different kinds of exchanges and bindings and there is no silver bullet. However, when I’ve started working with it, I needed some basic guidance on how to organize microservices communication, e.g. how to create topology, name exchanges, queues, and routing keys and not to create a ball of mud with the grow of application. Here, I want to share my experience and show on a simple example how microservice communication might be organized.
Basics
I do not want to describe all the basics, e.g. what is producer, consumer, exchange, queue, routing key and how they are related to each other. Official documentation describes it in a simple and clear way with good examples. So if you completely new to RabbitMQ, please get familiar with the basics first.
Application
Let’s consider a simple application that imitates a store. Customers can place orders, warehouse should be notified about changes to be able to book or release necessary amount of goods. And we need to gather some statistics on order creation. So we have 3 services that should interact: order, warehouse and statistics.
Default exchange
To organize RabbitMQ topology the simplest way is to use the default exchange. You can bind queues to it and messages would be routed to them if routing key matches queue name.
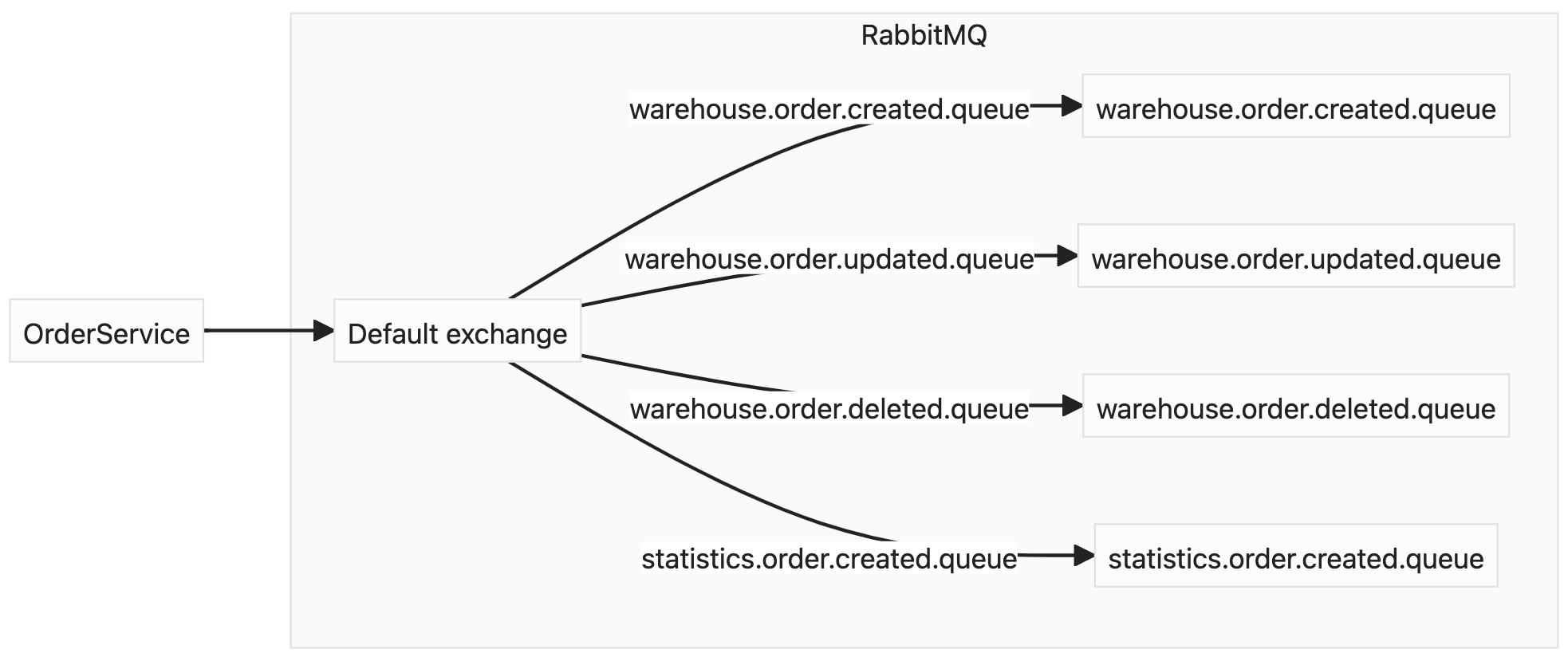
In our example we can send messages to default exchange and set queue name that corresponds to the CRUD operations.
Even though the approach is simple, the biggest downside of it, is that consumer should be aware of queues bound to the exchange and it might implicitly depend on consumers. E.g. if we need to notify both warehouse and statistics services on order creation, we need to send events with different routing keys related to each consumer.
Despite the fact that default queue does not that flexible for our example, it can be useful to implement retry patterns.
Fanout exchange
Another type of exchange we can use is fanout. It completely ignores routing keys and deliver messages to every queue bound to it. Services might check amqp_type or other custom header to decide should a message be processed and how.
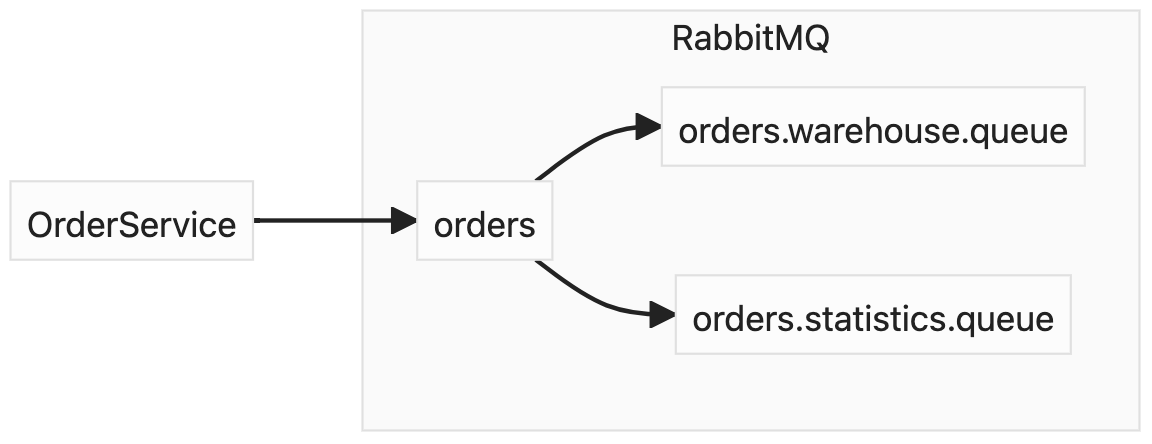
We can use that type of exchange if the most messages should be delivered to every consumer. However, in our case, statistics service need to receive only subset of events and with the described topology it would be forced to receive other types of messages and just skip them.
Direct exchange
Direct exchange would make our topology much better as it delivers messages to queues bound to exchange with appropriate routing key. So we can define a dedicated routing key for each operation and consumers might subscribe only to messages they are interested in.
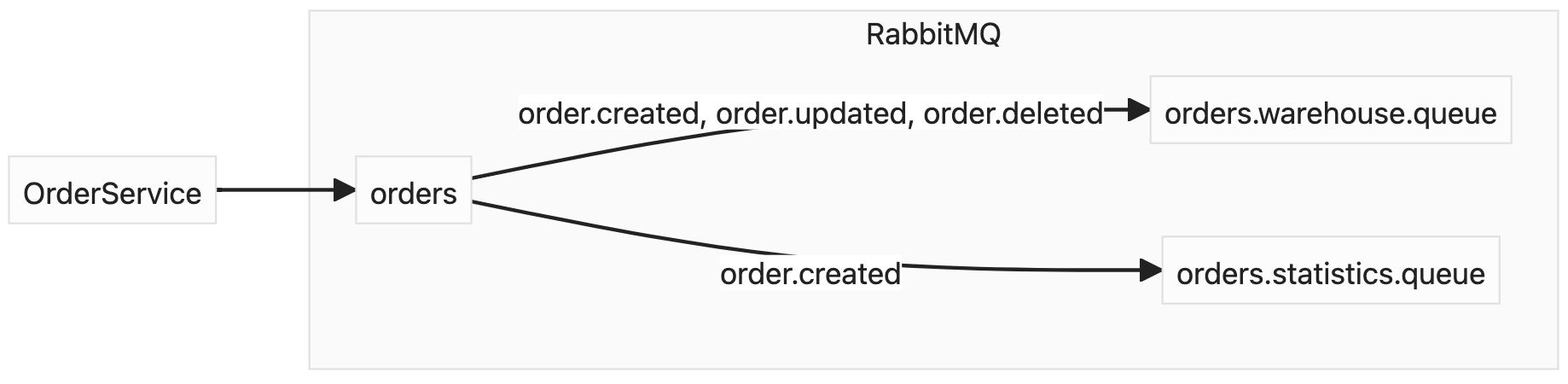
Here orders.statistics.queue is bound with order.created routing key, so it would receive only messages that match it. At the same time orders.warehouse.queue would get messages with all CRUD routing keys.
Topic exchange
And another type of exchanges I wanted to mention is the topic one. It works similar to direct exchange, however, we can use special symbols in routing keys on binding:
#- matches zero or more words*- matches a single word
So if we have potentially indefinite number of routing keys, we can write kind of regex to handle all the messages, which routing keys match it.
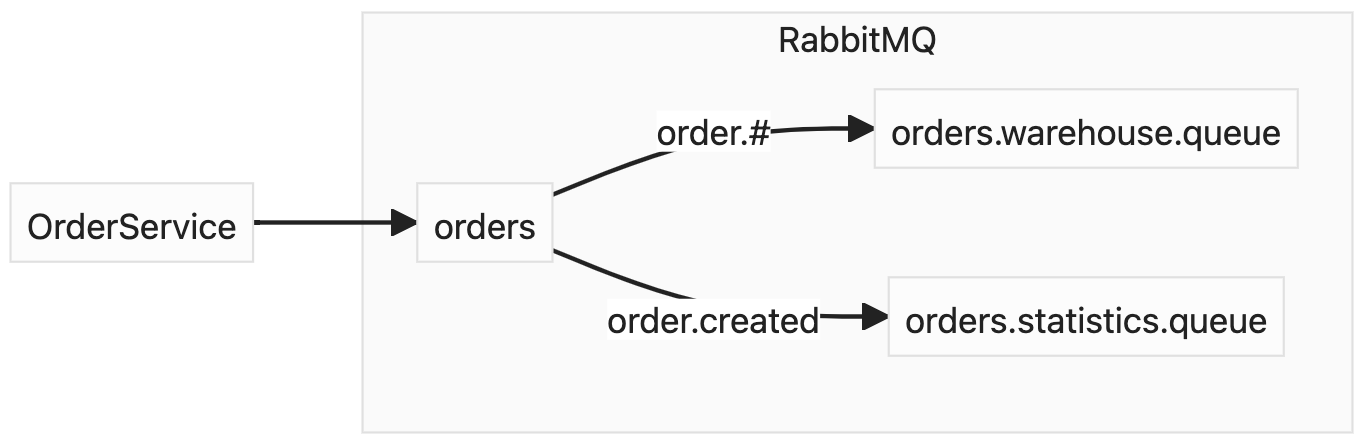
If we want warehouse to receive all the updates on order entity, we can provide order.# routing key. And if would have another routing keys in the future, there would be no need in changing queue binding.